Scalable, Lie-Detecting Timeserving with Roughtime
CONTENTS[Addendum: related Hacker News discussion]
Roughtime is a protocol designed to provide internet-scale secure time synchronization and address shortcomings of older protocols like NTP.
Why This Matters
Many aspects of day-to-day computing assume an accurate local clock. This assumption extends to security-critical operations like certificate expiry, OSCP stapling, and Kerberos tickets. An attacker that subverts time sync could violate the security of these operations.
The dominant internet time-sync protocol, Network Time Protocol (NTP), is showing its age. Amongst other things:
- It is unauthenticated1 and most clients blindly trust the reply of any server (
pool.ntp.organyone?). - Clients that find an NTP server responding with bad values have no way to prove to others that a particular server is a bad actor2.
- There are protocol (mis)features that can be abused to create DDoS traffic3.
Roughtime Goals
Roughtime attempts to improve on the status quo. Paraphrasing its design goals:
- Accuracy in seconds – The protocol aims to get local clocks within a few seconds of the “true” time. The Roughtime creators state that 25% of Chrome’s certificate errors are caused by incorrect local clocks (off by days or more). A local clock within a few seconds of reference time is good enough.
- Secure – Roughtime servers sign every reply and the signature is verifiable by any client. Clients can build a chain of replies to establish proof of server misbehavior. This proof is also verifiable by any client. No central trust is required.
- Internet scalable – The protocol is stateless and built upon efficient and batchable operations. The network layer is constructed to prevent DDoS amplification.
- Healthy ecosystem – Roughtime includes mechanisms for ensuring “freshness” of clients and correctness of their implementations. The intent is to surface bugs quickly and mitigate abusive client practices4.
Bellow I’ll explore some of the interesting aspects of Roughtime that may not be immediately obvious.
Aside: Roughtime In a Nutshell
For those unfamiliar, below is a very abbreviated description of how Roughtime works. The specification and project page details the actual protocol:
- A brand new client generates a 64 byte random nonce and sends it to a Roughtime server.
- The Roughtime server replies with the current time, the client’s nonce, and a signature of both.
- Subsequent client requests generate their nonce by combining the reply in #2 with a random value (a blind5).
Clients know that server responses are A) fresh because they include their nonce, and B) authentic because they are signed.
By deriving future requests from prior responses, the client establishes a chain of happens-before ordering between requests and replies.
Sending chained requests to multiple servers extends the total order across all participating servers (e.g. send
Ato server1 and receiveA'; sendB = sha512(A')to server2 and receiveB'; sendC = sha512(B')to server3 and receiveC', and so on).
Scalable Request Processing
A Roughtime server signs its responses using the Ed25519 public-key signature system. Ed25519 signatures are quite fast: according to eBATS an Intel Skylake CPU takes about ~49,000 cycles to compute an Ed25519 signature. Assuming a 3.0 GHz clock speed that’s ~61,000 signatures per second on a single core. Signatures are also compact: 64 bytes each.
To scale the signing workload, Roughtime uses a Merkle Tree to sign a batch of client requests with a single signature operation. The root of the tree is signed and included in all responses. With a batch size6 of 64 a single 3.0 GHz Skylake core can sign 3.9 million requests per second.
Another design feature helps limit per-client processing: the non-client-specific parts of a response are identical for all replies in a single batch7. Servers can calculate these values once and re-use them in each reply.
Anti-Amplification Request/Response Size Asymmetry
All Roughtime requests are required to be at least 1024 bytes long and any request shorter is simply dropped. Why? To ensure that a Roughtime server cannot be used as a DDoS amplifier.
| Roughtime Message | Size (bytes) |
|---|---|
| Client Request | 1024 |
| Server Response to a single request | 360 |
| Server Response when batching 64 requests | 744 |
The 1 KiB request size requirement ensures an attacker has no size gain on traffic sent to a Roughtime server; replies are always smaller than requests, even under load (when batching responses).
This also naturally rate-limits requests: at 1 KiB per request a 10 Gbps link can deliver a maximum of 1.2 million requests per second. As shown above, that rate is easily handled by a single Skylake core.
Keeping Response Sizes Compact
You probably noticed the response size when batching 64 requests is suspiciously small: 744 bytes. This is not a typo.
Recall that Roughtime uses a Merkle Tree of client requests to construct its batched response. A Roughtime server does not send the whole tree when replying to clients. It sends the signed root plus only those nodes each client needs to verify that its request was included in the tree8. Being a complete tree, the maximum number of path elements required by any client is ceil(log2(batch size)).
An example might help. Consider this simplified Merkle Tree constructed from seven requests, A though G:
_____ h(ABCD|EFG) _____
/ \
h(AB|CD) h(EF|G)
/ \ / \
h(A|B) h(C|D) h(E|F) h(G)
/ \ / \ / \
h(A) h(B) h(C) h(D) h(E) h(F)
h(...) = SHA512
Imagine constructing a response to client C that needs to verify its request C is in the tree:
- To compute
h(C|D)the client needsh(D)(client C remembers theh(C)it sent). - To compute
h(AB|CD)the client already hash(C|D)from step #1, so it needsh(A|B). - For the root,
h(ABCD|EFG), the client hash(AB|CD)from step #2 and needsh(EF|G).
Thus client C is sent h(D), h(A|B), and h(EF|G).
Hopefully it’s clearer how the 744 byte response size for a server batching 64 requests is obtained: ceil(log2(64)) == 6 and 6 * 64 bytes per sha512 == 384 bytes. Minimum Roughtime response size of 360 bytes + 384 bytes of tree path data = 744 bytes total.
Catching Lying Servers
Now to examine how request/response chaining allows clients to detect and tattle on misbehaving servers. The diagram below illustrates a sequence of chained requests and responses between one client and two servers:
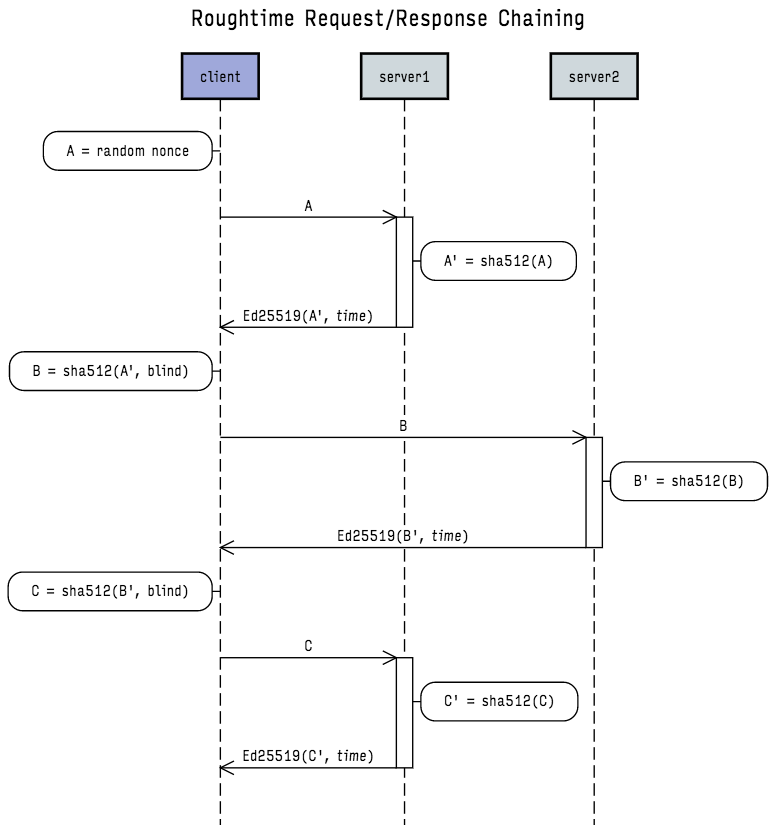
Figure 1 - Roughtime request/response chaining (click to enlarge)
Proof of server misbehavior emerges from two interlocking properties of the protocol:
- Chaining establishes total ordering between all request/responses. Composing requests using prior responses establishes a single sequence of events that can be independently verified.
- All responses are cryptographically signed. Signatures establish authenticity of responses, identity of senders, and prevent forgery.
A client sending nonce B which was derived from A can be certain that response B' (and the time associated with it) came after response A' (and its associated time). If the client sees a time in response B' that is before the time in A' then something is obviously wrong.
By querying several servers (assuming no collusion) a client can identify not only ordering issues but also time quality problems. One server reporting a time way off the others will be obvious and the collection of cross-signed request/responses will supply proof.
A client can store a log of request and response chains. There are no secret values in Roughtime requests or responses so this log can be provided to an audit service or other third-party. This protobuf definition from the Roughtime project is intended as the standard JSON format for such chain files.
Closing Thoughts
Roughtime is elegant and simple but several of its clever features only become apparent after digging in. Hopefully this post helps spread the word. I didn’t touch on other neat ideas in Roughtime like deliberate response fault injection or use of key delegation to limit exposure of long-term keys.
If you’re interested in learning more:
- The project page should be your first stop. The reference C++ and Go implementations live there.
- I wrote Nearenough, a Java implementation of Roughtime. It can pretty-print Roughtime messages if you need to do that sort of thing.
- Two good Hacker News discussions around the time of the initial project announcement: one and two.
-
Yes, there are authentication mechanisms in NTPv4 as well as in-development NTP/PTP authentication protocols like NTS. None of these have seen widespread deployment on the public internet, in mobile devices, or as out-of-the-box OS defaults. Furthermore these solutions require that clients unconditionally trust one or more servers and/or require computationally expensive handshakes. ↩︎
-
“Proof” in this case being a cryptographically secure record that can be audited by an untrusted third party. Think spiritual cousin of certificate transparency. ↩︎
-
Granted correctly configured NTP servers will not have these issues…and all internet accessible devices are always correctly configured, right? ↩︎
-
The randomness makes subsequent request values unpredictable. ↩︎
-
Batching sizes are not part of the specification. 64 is used as it makes a convenient example and corresponds to a reasonable UDP buffer size (64 KiB). ↩︎
-
Specifically only the
PATHandINDXtags vary response-to-response. TheSIG,SREP, andCERTtags will be identical in all responses. ↩︎